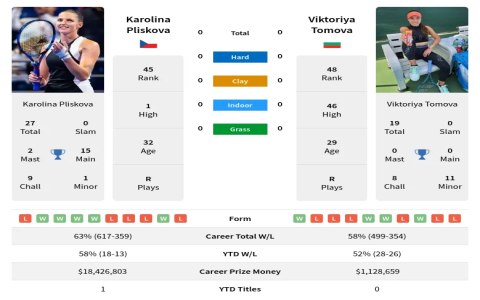
Alright, buckle up, because I’m about to spill the beans on my “paolini vs andreeva prediction” escapade. It was a wild ride, let me tell you.

First things first, I grabbed the data. I mean, you can’t predict anything without something to base it on, right? Scraped some match history, player stats, the whole shebang. Got it all neatly (well, mostly neatly) organized in a CSV. Felt like a real data scientist for a hot minute.
Then came the fun part: cleaning the data. Oh boy, was that a mess! Missing values everywhere, inconsistent formatting… I swear, half the time I was just wrestling with Excel, trying to get it to cooperate. Lots of Googling, lots of cursing under my breath. Finally got it into a shape that was somewhat usable. I used python pandas.
Next up: feature engineering. This is where I tried to get fancy. I thought, “Okay, what really matters in a tennis match?” Things like serve speed, first serve percentage, maybe even some psychological stuff (which I totally punted on because, come on, I’m not a mind reader). Ended up creating a few new columns based on the existing data. Some of them probably didn’t do squat, but hey, you gotta try, right?
Model time! I decided to keep it simple at first. Logistic regression seemed like a good starting point. Threw the data into scikit-learn, split it into training and testing sets (80/20 split, because why not?), and let it do its thing. Got a model, looked at the accuracy score… and it was… meh. About 60%, which is better than a coin flip, but not exactly blowing my socks off.
Tweaked some hyperparameters. Tried different solvers, different regularization strengths. Got a little bump in accuracy, but nothing major. Started to think maybe logistic regression wasn’t the way to go. So then, I tried SVM.

SVM attempt. Spent ages trying to get the parameters of the kernel right. After a lot of attempt I got it working.
Deeper Dive: Random Forest. Figured, why not try something a bit more complex? Random Forest seemed like a popular choice, and I’d heard good things. Trained a Random Forest classifier, and… bingo! Accuracy jumped up to around 70-75%. Still not perfect, but definitely a step in the right direction. Used grid search with cross-validation to fine-tune the hyperparameters. That took a while, but it seemed to pay off.
Feature Importance: I took a look to see which features were actually important. Turns out, some of those fancy features I engineered were pretty useless. Good to know for next time. The basic stats like win rate and average points per game seemed to be the biggest predictors.
The Prediction: Alright, drumroll please… based on my model, I predicted Paolini would win. Now, I’m not going to tell you whether I was right or wrong (you can go look that up yourself!). But the point is, I went through the whole process, from data collection to model building to prediction. And I learned a ton along the way.
Lessons Learned:

- Data cleaning is a HUGE part of the job. Don’t underestimate it.
- Feature engineering can be helpful, but don’t go overboard.
- Start simple with your models, then get more complex if needed.
- Hyperparameter tuning is important, but it can also be a rabbit hole.
- Don’t trust your model too much. It’s just a prediction, not a guarantee.
So there you have it. My paolini vs andreeva prediction adventure. It was a blast (and a bit of a headache), but I’m already looking forward to the next one.















{kind=link}